Die Diskussion in den meisten AI-Threads dreht sich um die falsche Achse. Welches Modell ist besser, Claude oder GPT, welche Version, welche Effort-Stufe. Das ist die Frage von vorgestern. Inzwischen sind die Top-Modelle so nah beieinander, dass die Unterschiede in der Praxis kaum noch durchschlagen.
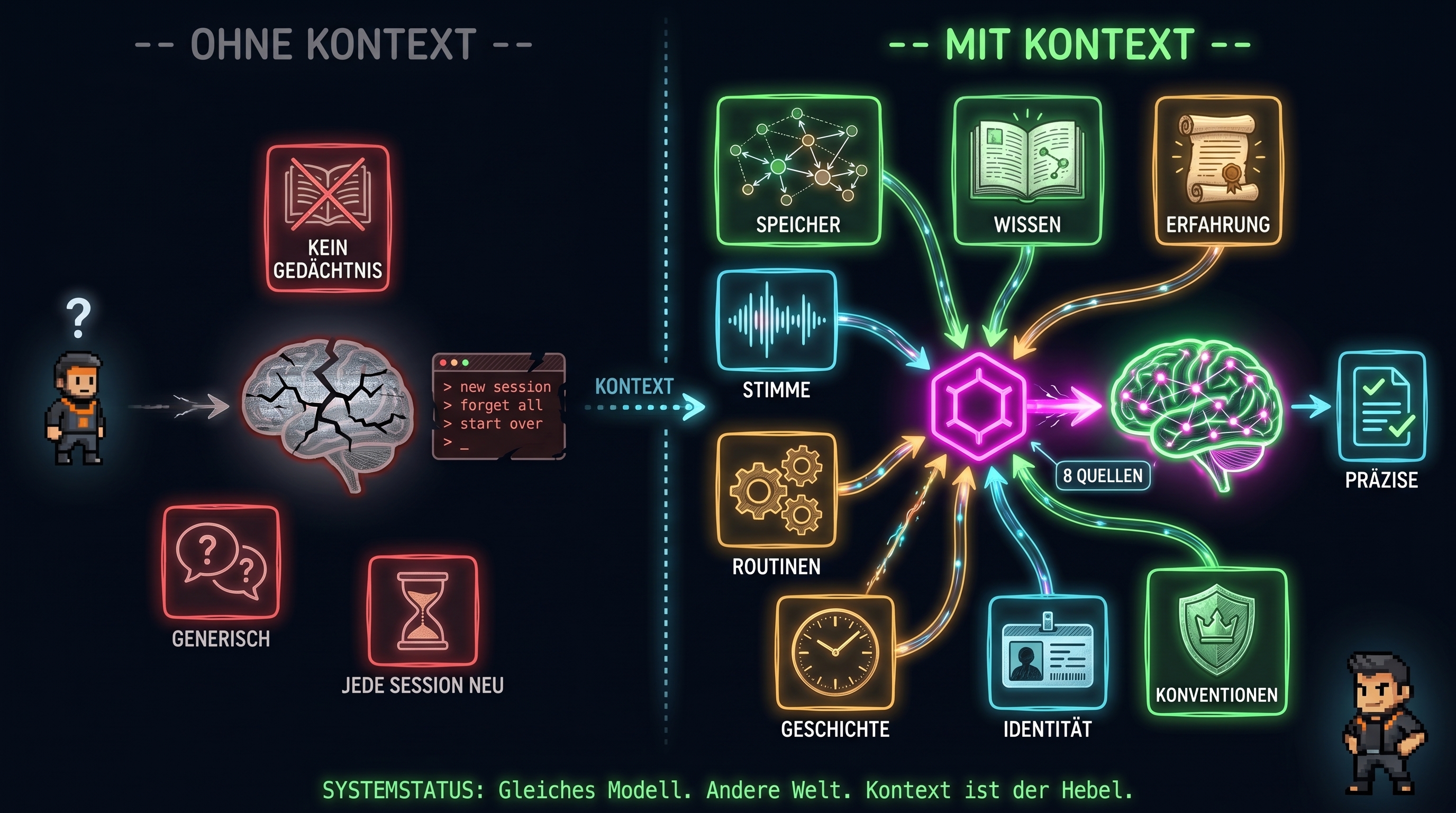
Was den Unterschied macht, ist eine Schicht davor: der Kontext, den das Modell vor dem Generieren sieht. Bessere Inputs auf einem schwächeren Modell schlagen fast immer schlechtere Inputs auf einem stärkeren. Das ist die zentrale Aussage von Context Engineering, und sie hält jeden Tag der Woche.
Was Context Engineering wirklich ist
Context Engineering ist nicht das Schreiben besserer Prompts. Es ist die ganze Pipeline davor. Was sieht das Modell, in welcher Reihenfolge, mit welcher Gewichtung. Welche Dateien sind geladen, welche Skills aktiv, welche Memory-Ebenen liefern den Hintergrund, welche Konventionen gelten.
Wenn ein Output schwach wirkt, ist die ehrliche erste Frage selten “war das Modell zu klein?” sondern “was hat das Modell überhaupt gewusst?”. In neun von zehn Fällen liegt es am Kontext.
Drei Schichten
Bei DON arbeite ich mit drei Memory-Ebenen, die unterschiedliche Lebensdauern haben.
Session. Die laufende Konversation. Kurzlebig, hoch dynamisch, nur für die aktuelle Aufgabe gedacht. Hier landet alles, was während eines Builds an Reibung entsteht.
Project. CLAUDE.md, Repo-spezifische Konventionen, Skills, die zu diesem Projekt gehören. Persistent über Sessions hinweg, aber projektgebunden. Für DON heißt das: Code-Stil, Git-Konventionen, Vault-Pfade, alles was systemweit gilt.
Vault. Obsidian. Über alle Projekte hinweg verfügbar. Hier liegen Ziele, Erkenntnisse, Voice-Regeln, Concept-Pages, Personenbeziehungen. Was länger als ein Quartal trägt, gehört hier hin.
Wer die Ebenen vermischt, bekommt Rauschen. Persönliche Voice-Regeln in einem Repo zu vergraben heißt, dass sie in keinem anderen Projekt greifen. Projekt-Konventionen in den Vault zu schieben heißt, sie für andere Projekte irrelevant in die Lage zu legen. Saubere Trennung ist die Basis.
Warum es sich aufbaut
Kontext zahlt sich nicht-linear aus. Eine CLAUDE.md am Tag eins ist nett. Nach drei Monaten ist sie der Grund, warum jede Session direkt produktiv startet, ohne Re-Briefing. Eine Voice-Page nach zwei Wochen ist Hygiene. Nach einem halben Jahr formt sie jeden Output, ohne dass ich nochmal drüber nachdenken muss.
Genau deshalb ist Context Engineering eines der wenigen Themen, bei denen Frühstart entscheidend ist. Wer erst nach zwei Jahren anfängt, hat zwei Jahre lang ohne Hebel gearbeitet. Die Modelle werden besser, ja. Dein Kontext bleibt deiner.
Was das praktisch heißt
Wenn du heute anfangen willst, reichen drei Dateien:
- Eine Datei für Identität. Wer bist du, was machst du, wie redest du. Ein Absatz pro Frage genügt.
- Eine Datei pro Projekt. Konventionen, Pfade, Stack, Sonderregeln. Die liest jede Session zuerst.
- Eine Datei für Lessons. Was hat dich Zeit gekostet, was würdest du nicht nochmal machen. Lebenslang gepflegt.
Mehr brauchst du anfangs nicht. Skills, Hooks, Memory-Layer, MCP-Server, all das kommt später, wenn die Basis steht.
Die Modellwahl wird sich in den nächsten zwei Jahren noch dreimal ändern. Dein Kontext bleibt.